
훅 — 인생의 영원한 딜레마
단골 김밥집 vs 새로 생긴 태국 식당. 오랜 친구 vs 새로 만난 지인. 좋아하는 노래 vs 막 발매된 신곡. 이 모든 결정은 같은 구조입니다 — 탐색(explore)할 것인가, 활용(exploit)할 것인가?
컴퓨터 과학자들은 이 문제를 다중 슬롯머신 문제(Multi-Armed Bandit)라 부릅니다. 슬롯머신을 "one-armed bandit"(한 팔의 강도)이라 부르는 데서 유래했죠. 2차 대전 중 연합군 분석가들은 이 문제가 너무 시간을 잡아먹어서 "독일에 떨어뜨려 지적 사보타주를 일으키자"는 농담까지 했다고 합니다.

핵심 통찰
Interval이 전략을 결정한다
🔑모든 것은 '남은 시간'에 달렸다
이 통찰은 노화의 "비밀"도 풀어줍니다. 스탠퍼드의 Laura Carstensen은 노인의 사회적 네트워크 축소를 무능력이 아닌 합리적 선택으로 설명합니다. 청년은 책 저자나 새 친구를 선호하고, 노인은 가족과 30분 보내기를 선호합니다. 그러나 청년에게 "곧 다른 도시로 이사한다"고 가정하면 가족을 선호하고, 노인에게 "20년 더 살 수 있는 의학 발견이 있다"고 가정하면 청년처럼 행동합니다. 나이가 아니라 interval이 결정합니다.
직접 해보기
식당 고르기 게임
🎰 식당 고르기 — UCB1 vs 직감
총 0번 · 만족 0번
4개 식당의 실제 만족 확률은 숨겨져 있습니다. 직접 골라보거나, UCB1 알고리즘의 추천을 따라가 보세요. UCB1은 "관측된 평균 + 불확실성 보너스"가 가장 큰 식당을 고릅니다 — 불확실성 앞에서의 낙관주의.
최근 결과 (좌→우)
식당을 클릭해 시작하세요
💡 다중 슬롯머신 문제(Multi-Armed Bandit). UCB1은 시도 횟수가 적은 식당일수록 보너스를 더 줘서 자동으로 explore하다가, 표본이 쌓이면 보너스가 줄어 자연스레 exploit으로 전환합니다. 후회(regret)는 로그적으로만 늘어나는 것이 보장됩니다.
알고리즘의 진화
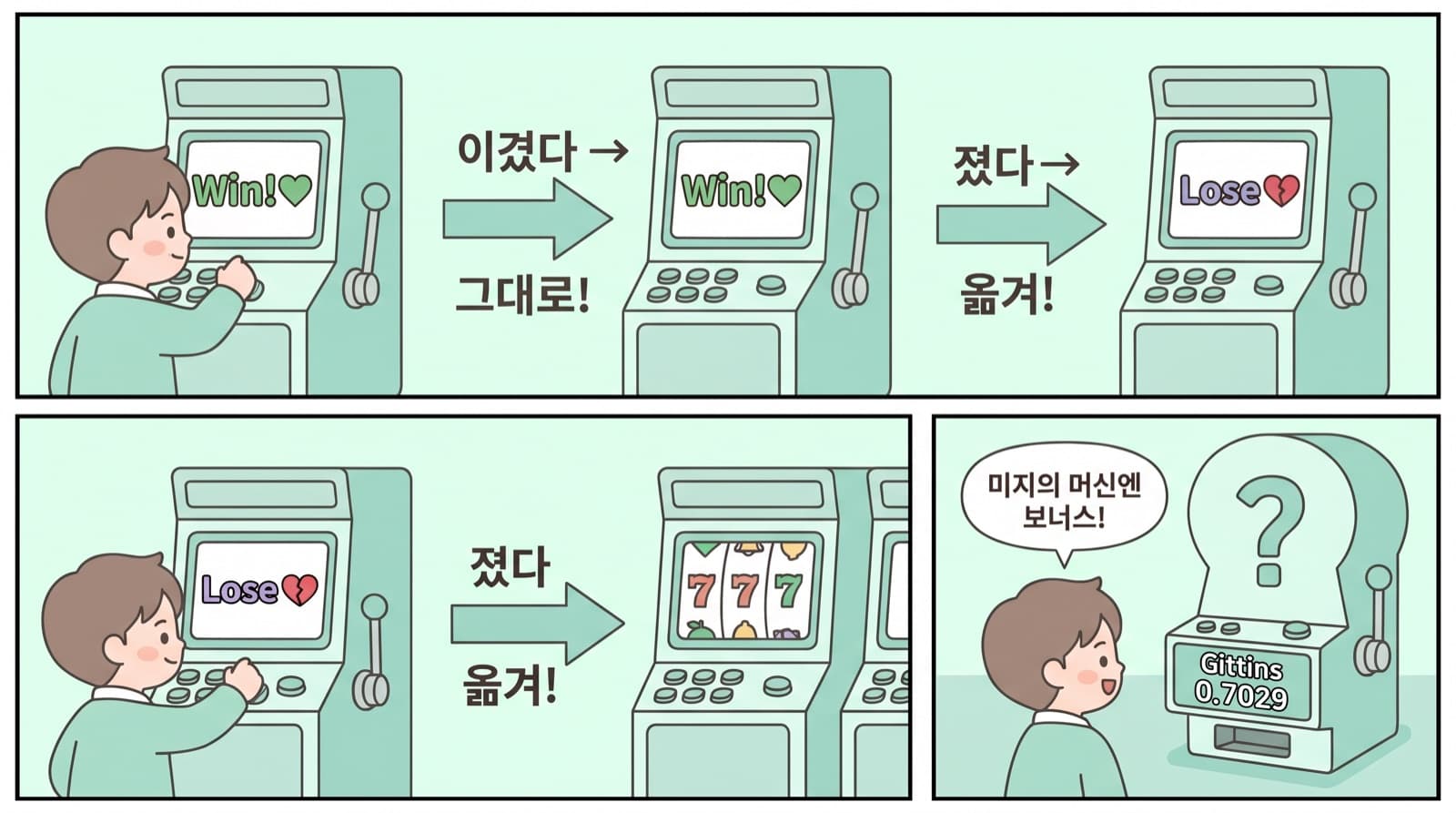
가장 단순한 규칙 — 이기면 계속, 지면 다른 머신으로. 우연보다는 확실히 낫습니다. "Stay on a winner" 원칙은 거의 모든 최적 전략의 일부입니다.
영국 Unilever가 John Gittins에게 약품 시험 최적화를 의뢰하면서 탄생했습니다. 각 머신마다 "이 머신을 영원히 안 당기는 대신 받을 만한 보장된 보상"(뇌물!)을 계산해 가장 높은 인덱스를 가진 머신을 선택합니다.
놀라운 사실: 0-0 기록(완전히 모르는 머신)의 인덱스가 0.7029로, 7/10 성공한 머신(0.6300)보다도 높습니다. 미지에는 가치가 있습니다.
"Upper Confidence Bound" — 신뢰구간의 상한선이 가장 높은 옵션을 선택. "잘 모르겠지만 어쩌면 최고일 수도?"라는 기대감이 새로움에 보너스를 줍니다.

A/B 테스트의 현장
구글 PM이었던 Siroker는 휴직하고 오바마 캠프에 합류, 후원 페이지를 A/B 테스트했습니다. 결과:
- 첫 방문자 → "DONATE AND GET A GIFT"가 최고
- 뉴스레터 구독자 → "PLEASE DONATE" (죄책감 자극)
- 기존 기부자 → "CONTRIBUTE" (이미 donate했으니까)
- 흑백 가족사진이 모든 영상/사진을 압도
결과: $5,700만 추가 모금. Siroker는 후에 Optimizely를 공동 창업합니다.
D. E. Shaw에서 안정적 직장을 그만두고 Amazon 창업을 결심한 이유: "80세의 나로 시간 여행해서 후회를 최소화하라." 시도하지 않은 것은 평생 나를 괴롭깁니다.
윤리적 시험
ECMO와 적응형 임상시험
1970년대 Robert Bartlett이 개발한 신생아 호흡부전 치료법 ECMO. 1982-84년 미시간대 연구는 Marvin Zelen의 "Play the winner" 적응형 알고리즘을 사용했습니다 — 성공한 치료의 공을 모자에 추가하는 방식.
- 한 명만 기존 치료받고 사망
- 11명 연속 ECMO 받고 모두 생존
- 8명 추가 ECMO도 모두 생존
- 기존 치료 2명은 모두 사망
후회의 수학
O(log n)
후회 최소화 한계
Lai-Robbins(1985): 후회는 절대 줄지 않지만, 최적 전략은 후회의 증가율이 로그 함수로 가장 느립니다. 첫 10번의 실수 = 다음 90번 = 그 다음 900번.
"탐색 그 자체에 가치가 있다. 불안한 세계에서 살려면 자신 안에도 어떤 불안함이 필요하다."
실생활 적용
- 🍽️ 식당 선택: 새 도시 도착 직후엔 explore, 떠나기 전엔 exploit.
- 👶 양육: 아이의 산만함과 호기심은 결함이 아니라 탐색 단계의 합리적 행동.
- 🎬 영화/책: 청년기 다양하게, 노년기 의미 있는 소수에 집중.
- 💼 창업: Bezos의 "80세 후회 최소화"를 자문해 보라.
Reflection
고민해 볼 질문들
정답이 정해져 있지 않은 열린 질문입니다. 혼자 생각해 보거나, 가까운 사람과 함께 이야기 나눠 보세요.
- 01
지금 당신의 인생은 explore(탐색)에 가까운가요, exploit(활용)에 가까운가요? 그 시기는 자연스러운가요, 강요된 것인가요?
- 02
새로움을 너무 자주 추구해서 잃은 것은 무엇이었고, 안전함만 좇아서 놓친 것은 무엇이었나요?
- 03
베조스의 '80세의 나'가 지금의 당신에게 보내는 메시지가 있다면 무엇일까요?
- 04
어떤 영역에서 당신은 단골(exploit)을 만들고, 어떤 영역에서 끊임없이 탐색하나요? 그 경계는 합리적인가요?